

Chaque forme de langage possède ses codes, ses signes et ses ambiguïtés. Demandez à un moteur de recherche de comprendre notre langage et vous comprenez déjà à quoi peuvent servir les entités nommées. Leur compréhension et leur utilisation par les machines a permis d’obtenir des résultats toujours plus personnalisés et plus précis. En comprenant les liens entre les différentes entités d’une page web ou d’un document, les moteurs de recherche peuvent améliorer la précision et la pertinence des résultats. Explications.
Entité nommée, de quoi parle-t-on ?
Selon Kristian Balog, une entité nommée est : « un objet ou une chose identifiable de manière unique, caractérisé par son ou ses noms, son ou ses types, ses attributs et ses relations avec d’autres entités », source Entity Oriented Search.

Selon Google, « une entité est une chose ou un concept singulier, unique, bien défini et distinguable. Par exemple, une entité peut être une personne, un lieu, un objet, une idée, un concept abstrait, un élément concret, une autre chose appropriée ou toute combinaison de ceux-ci. Par exemple, la couleur « Bleu », la ville « San Francisco » et l’animal imaginaire « Licorne » peuvent chacun être des entités”, source brevet Google, https://patents.google.com/patent/WO2014089776A1/en.
Les différents types d’entités nommés
Les entités nommées sont réparties en 7 types primaires :
- Personnes : personnes individuelles, personnes collectives. Exemple : Larry Page, Sundar Pichai ou Simone Weil.
- Lieux ou emplacements : lieux administratifs (ville, région, nations, états), lieux physiques (géographiques, hydrologiques, astrologiques) comme Paris, Silicon Valley, planète Mars ou la Californie.
- Organisations : entreprises, administrations et institutions, comme Google, Nike, Apple, Alphabet ou NASA.
- Temps et période : dates et horaires (absolus ou relatifs). Exemple : 14 juillet 1789, les années 1990, Jeux Olympiques, Attentats du 11 septembre 2001 ou la Révolution française.
- Les Quantités : les montants numériques, pourcentages et autres valeurs chiffrées, comme les kilomètres ou le chiffre 5 millions d’euros.
- Produits/objets : objets manufacturés, œuvres artistiques, œuvres médiatiques, produits financiers, logiciels, récompenses, voies, doctrines et lois. Exemples : iPad ou Statue de la Liberté.
- Fonctions : fonctions individuelles et fonctions collectives.
En complément, vous pouvez retrouver un autre document, de Satoshi Sekine Kiyoshi Sudo Chikashi Nobata, Extended Named Entity où l’auteur répertorie et hiérarchise plus de 160 types d’entités.
Obtenir l’amour de Google
Jugées ésotériques, les entités nommées sont, souvent, à tort délaissées. Pourtant, toute personne qui améliore les bases de connaissances, la reconnaissance des entités et l’exploration des informations, obtiendra l’amour de Google.

Mieux communiquer avec les machines
Comprendre les entités nommées et leurs relations, transmettre cette compréhension aux moteurs de recherche, c’est comme leur permettre de lire à travers votre pensée (ou plus précisément votre intention de recherche).
En travaillant vos contenus avec les entités, les algorithmes ont la possibilité de mieux scruter le contenu de vos pages web et de vous comprendre, comme le ferait un humain lorsque vous dialoguez avec lui.
Et lorsque Google interprète et comprend votre contenu, cela a un impact significatif sur votre classement et visibilité en SEO (si les deux autres piliers, la technique et la popularité sont travaillés également).

Mieux comprendre l’intention de recherche
Google peut déterminer si votre document possède des informations uniques. Si vous fournissez un contenu qui couvre l’intégralité d’un sujet, si vous ajoutez un niveau de profondeur rare, nouveau ou de l’expertise, alors vous répondez à ce que le moteur de recherche attend de vous.
En démontrant votre expertise et en amenant un côté holistique, vous devenez le maître de votre sujet.
Plongée dans le monde des entités nommées
Le domaine de la reconnaissance d’entités nommées (NER ou Named Entity Recognition) et de l’analyse du langage naturel (NLP) est fascinant et en constante évolution. Explorer ce monde vous permet de comprendre les concepts clés et de découvrir comment ils sont utilisés par les moteurs de recherche.
NLP et NER, de quoi parle-t-on ?
Voici les définitions du NLP et NER.
Définition du NLP
Le Natural Language Processing (NLP) est un domaine qui réunit la linguistique, l’informatique et l’intelligence artificielle (IA). Il est mis en oeuvre dans des applications informatiques qui impliquent l’interaction entre le langage humain et les machines. Le NLP ou TALN (Traitement Automatique du Langage Naturel) permet d’extraire automatiquement de l’information à partir de documents textuels, audio et vidéo.
Définition du NER
Le NER (ou Named Entity Recognition), une technique basée sur le machine learning. La reconnaissance des entités nommées (NER) consiste à identifier et à classer des entités spécifiques dans un corpus (ensemble de textes) et à leur attribuer des étiquettes appropriées telles que « nom », « lieu », « date », « organisation » ou « personne ».
La reconnaissance d’entités nommées : apprentissage de notre langage par les machines
Lorsque nous rencontrons un mot ou lisons un texte, notre capacité et notre apprentissage du langage nous permet d’identifier et de classer le mot en fonction des personnes, des lieux, des endroits, des valeurs, etc.
Nous sommes ainsi capables de reconnaître rapidement un mot, de le classer et d’en saisir le sens dans un contexte particulier.
Prenons, par exemple, le mot « la Joconde » de Léonard de Vinci.
Instantanément, nous pouvons associer ce mot à de multiples attributs et classer l’individu en conséquence : peintre, artiste de la Renaissance, tableau, etc… Cela vous semble logique, mais il a fallu aux datascientists apprendre aux machines toutes ces associations.

On retrouve également cet apprentissage de connaissances en recherche visuelle.
Identifier et classer automatiquement les éléments importants d’un texte
Les ordinateurs ne disposent pas de cette capacité innée à identifier et catégoriser les mots ou les textes. La reconnaissance des entités nommées (NER) leur est donc est nécessaire pour identifier et classer automatiquement les éléments importants d’un texte (ou d’une image) dans des catégories prédéfinies, telles que les noms propres, les lieux et les organisations.
Cette technique fait partie intégrante de l’analyse du langage naturel.
Elle est possible grâce au machine learning et plus récemment grâce au deep learning. Si les entités sont très facilement reconnaissables dans un texte par un humain, l’automatisation de cette tâche ne se fait cependant pas sans difficultés pour un ordinateur.
Comment fonctionne la reconnaissance d’entités nommées ?
La NER repose sur des modèles statistiques et des bases de données pour identifier et classer les entités nommées dans un texte (ou dans une image).
Les algorithmes de machine learning sont entraînés sur de grands ensembles de données annotés manuellement pour apprendre à reconnaître les différents types d’entités.
Une fois le modèle formé, il est capable de traiter automatiquement les nouveaux textes et d’extraire les entités pertinentes.

Analyse du langage naturel : comprendre les entités nommées
Les entités, qui comprennent les individus, les lieux, les objets (et donc certaines idées et concepts), sont les composantes fondamentales de notre réalité.
C’est ce qui explique que les entités nommées sont essentielles à la recherche sémantique. Google étant un moteur de recherche sémantique, comprendre les entités nommées, c’est quelquepart, mieux comprendre « une infime partie » du fonctionnement du moteur de recherche.

Extraire les informations pertinentes
Les entités nommées visent à comprendre les requêtes et les intentions de recherche par un moteur de recherche à la manière d’un être humain, pour en extraire les informations pertinentes.
Les moteurs de recherche ont fait des progrès considérables dans la compréhension des liens entre ces entités. Ils sont donc désormais capables de mieux comprendre notre monde à la fois réel et abstrait.
Le résultat du moteur de recherche est donné à partir d’un graphe de connaissances. Ce dernier se réalisant grâce à « la pluralité de métriques indiquant la pertinence du résultat de recherche« , (…) et la pluralité de métriques étant déterminée au moins en partie à partir du graphe de connaissances, lui-même déterminé grâce aux types d’entités.
A savoir : « le système de recherche peut utiliser n’importe quelle métrique ou combinaison de métriques appropriée pour classer les résultats de recherche. On comprendra également que le système de recherche peut utiliser n’importe quelle technique de pondération appropriée pour combiner des métriques« , source brevet Google 2012.
Il faut comprendre par là que les entités ne sont pas le remède miracle ni le secret algorithmique du classement du moteur de recherche Google. Néanmoins, elles peuvent grandement vous aider à faire du « bon travail » et à être mieux compris des moteurs de recherche.
Les entités nommées sont comme des « clés » qui peuvent vous aider à mieux vous classer.
Les mots-clés, une époque révolue ?
Plus besoin de parler de mots-clés et de les mettre partout ! En effet, grâce aux entités, les moteurs de recherche fournissent aujourd’hui des résultats de recherche plus précis et plus pertinents pour les utilisateurs, tels que vous et moi.
Au-delà de la simple correspondance des mots-clés, la sophistication des algorithmes leur permet désormais de comprendre votre intention de recherche derrière presque chaque requête.
L’époque où l’on se contentait de faire correspondre des mots-clés à des pages web est révolue depuis longtemps. Les moteurs de recherche modernes sont devenus plus avancés et plus « intelligents ». Dans nos interactions quotidiennes, nous utilisons des phrases complètes qui forment un contexte cohérent plutôt que des mots-clés isolés.
Les entités nommées ont joué un rôle déterminant dans cette évolution. Auparavant, chaque mot était traité et analysé individuellement par un moteur de recherche comme Google.
Hummingbird en 2013 : mieux comprendre le sens des mots
Au cours des deux dernières décennies, les moteurs de recherche ont subi des changements importants (via Hummingbird, changement algorithmique en 2013), accordant une place plus importante aux entités nommées et aux mots-clés de longue traîne.
Les machines ont ainsi appris à comprendre le « sens des mots », d’une phrase et à interpréter notre langage grâce au NLP ou TALN (Traitement Automatique du Langage Naturel).
Selon Amit Singhal, chef de la recherche chez Google en 2013 : « Hummingbird » a été le changement le plus spectaculaire de l’algorithme depuis 2001″.
Cette mise à jour algorithmique a aussi permis de donner de meilleurs résultats pour les requêtes locales et l’affichage sur Google Maps.

Rankbrain et Bert
D’autres mises à jour ont eu leur importance : RankBrain en 2015 et BERT en 2019.
Google RankBrain et Google BERT sont deux technologies avancées qui améliorent la capacité de Google à comprendre et à répondre à différents types de requêtes de recherche. RankBrain utilise des entités et l’intelligence artificielle pour traiter efficacement les requêtes peu familières, et à comprendre le lien entre les mots et les concepts.
BERT, quant à lui, s’appuie sur le traitement du langage naturel (NLP) pour comprendre les intentions de recherche exprimées en langage naturel. Comme le mentionne Pandu Nayak, « BERT a représenté une étape majeure dans la compréhension du langage naturel, en nous aidant à comprendre comment les combinaisons de mots expriment différentes significations et intentions. Plutôt que de simplement rechercher du contenu correspondant à des mots individuels, BERT comprend comment une combinaison de mots exprime une idée complexe », source Blog Google The Keyword.
Cet algorithme permet au moteur de recherche Google de mieux analyser le contenu des pages web, d’être toujours plus pertinent et d’identifier les liens entre les différentes entités.
Le jeu du mot mystère
Ainsi, il ne s’agit plus de savoir si le terme de recherche exact apparaît sur votre page web. Vous devez utiliser vos mots et expressions en fonction de l’intention de recherche de l’utilisateur. Google peut maintenant rechercher des entités relatives sur votre page et tenter de lier ces entités à des entités associées sur l’ensemble de votre site. Vous pouvez donc très bien rédiger du contenu sans jamais mentionner le mot-clé mais vous positionner dessus grâce à :
- La pertinence de vos contenus.
- La qualité de vos écrits et sources.
- Votre autorité thématique sur le sujet.
Entité, requête et intention de recherche
Les entités jouent un rôle crucial dans diverses tâches pour les moteurs de recherche. Elles sont impliquées dans :
- l’interprétation des requêtes de recherche ;
- l’évaluation de la pertinence des documents ;
- l’évaluation de la qualité et de l’expertise du domaine (ou de l’auteur) ;
- l’affichage de réponses telles que des panels de connaissances ou Knowledge Graph.
Exemple de compréhension d’une requête grâce aux entités nommées
Pour mieux comprendre l’importance des entités nommées, prenons un exemple.
Lorsque vous recherchez « Orange », comment Google sait-il si vous parlez de l’opérateur de téléphonie, du fruit, de la ville française ou de la couleur orange ?
La réponse ?
Grâce aux entités nommées et leurs connexions.
En analysant le contexte et les entités interconnectées, Google peut comprendre que lorsque vous recherchez « Orange » avec hôtel, vous essayez de trouver un hébergement pour séjourner dans le Vaucluse, dans la ville d’Orange.
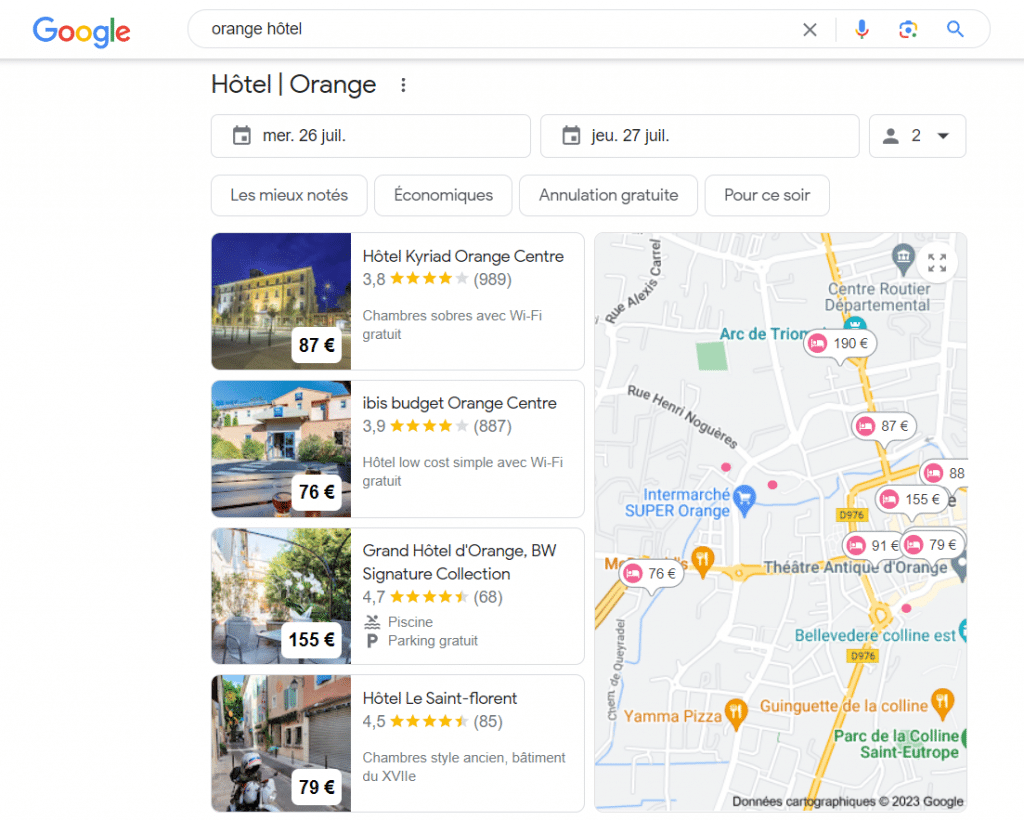
Si vous tapez sur votre clavier « orange et IPhone 14 Pro », le moteur de recherche peut comprendre que vous rechercher un téléphone Apple dans une boutique de téléphonie de la marque Orange.
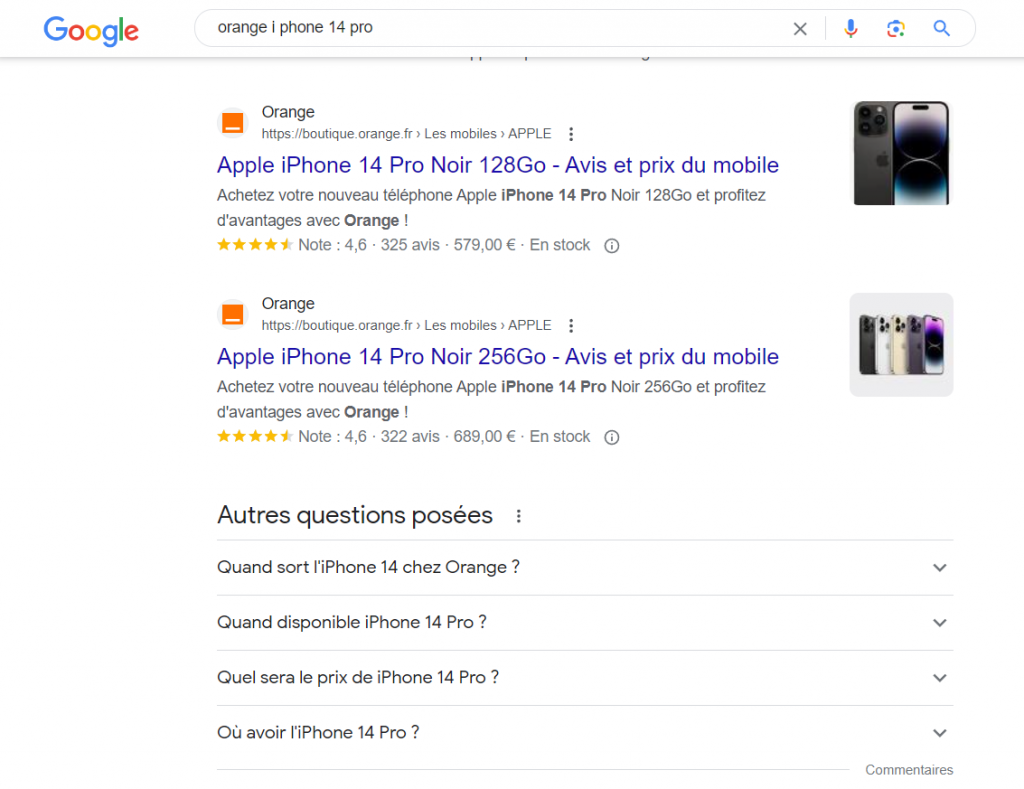
Le mot « orange » a donc des significations différentes selon le contexte. En comprenant le langage naturel, nous sommes capables d’en trouver le sens et de nourrir notre cerveau avec les informations dont il a besoin pour faire une déduction et comprendre ce qui se passe grâce à notre base de connaissances et à des points de référence.
Ainsi, même si le mot « orange » est mentioné sans aucun contexte, notre cerveau peut établir des connexions et comprendre implicitement de quoi nous voulons parler.
Mais comment permettre à Google d’en faire autant ? Toujours grâce aux entités nommées…
Entité Nommée
Une entité est un objet ou une chose qui peut être identifié de manière unique. Elle est caractérisée par son (ses) nom(s), son (ses) type(s), ses attributs et ses relations avec d’autres entités.
La compréhension de la pertinence d’un document par rapport à une requête est influencée par la connaissance des entités reconnaissables.
Propriété des entités
Les informations associées à une entité peuvent être regroupées en différentes propriétés :
identifiant unique, noms, types, attributs et relations entre entités.
Identifiant unique
Les entités doivent être identifiables de manière unique. Il doit y avoir une correspondance unique entre chaque identifiant d’entité (ID) et le (monde réel ou fictif), c’est-à-dire l’objet qu’il représente dans un catalogue d’entités donné. En effet, la même entité peut exister sous différents identifiants dans des catalogues.
Voici quelques exemples de catalogues d’entités :
- Wikipédia
- Wikidata
- DBpedia
- Freebase, acheté par Google en 2010
- Yago
- GeoNames
- OpenStreetMap
Il est important de noter que Wikipedia n’est pas le facteur décisif pour déterminer si quelque chose est une entité, mais cette encyclopédie en ligne est surtout connue pour sa base de données d’entités.
Wikipédia est une base de connaissances sur laquelle Google s’appuie pour améliorer sa compréhension et son utilisation des entités. En explorant ou en créant une page Wikipédia, vous pouvez approfondir votre connaissance des entités et de la recherche sémantique.
Nom d’une entité
Les entités sont connues et référencées par leur nom. Contrairement aux identifiants, les noms n’identifient pas de manière unique les entités ; plusieurs entités peuvent
partager le même nom ou être connues sous plusieurs noms (par exemple, « Barack Obama », « Président Obama », « Barack Hussein Obama II »). Pour les machines, automatiquement
la désambiguïsation des références d’entité présente de nombreux défis.
Types d’entités
Les types d’entités peuvent également être considérés comme des conteneurs (catégories sémantiques) qui regroupent des entités aux propriétés similaires.
L’ensemble des types d’entités possibles est souvent organisé selon une structure hiérarchique,
c’est-à-dire une taxonomie (ou diversité) de type. Par exemple, l’entité « Albert Einstein » est une instance de type « scientifique », qui est un sous-type de « personne ».
Les types d’entités peuvent comprendre des structures organisationnelles, des groupements et des caractéristiques de définition associées à une entité. On parle alors de « noeuds » entre entités pour dire qu’elles sont liées entre elle.
Par exemple, le nœud d’entité « George Washington » peut être connecté au nœud de type entité « Président » ou au nœud de type entité « Person ».
Entités et attributs
Les caractéristiques d’une entité sont décrites par un ensemble d’attributs. Différents types d’entités sont généralement caractérisés par différents ensembles d’attributs. Par exemple, les attributs d’une personne comprennent la date et le lieu de naissance, ses parents, conjoints, etc.
Les Attributs d’un lieu peuvent inclure la latitude, la longitude, la population, le ou les codes postaux, le pays, la région, etc.
Les résultats de la recherche sont extraits d’une structure de données. Dans certaines mises en œuvre, la structure de données contient également des données concernant les relations entre les rubriques, les liens, les informations contextuelles et d’autres informations liées aux résultats de recherche que le système peut utiliser pour déterminer les métriques de classement.
Par exemple, dans la phrase « Barack Obama a été président des États-Unis de 2009 à 2017 », « Barack Obama » est une entité nommée de type « personne », « 2009 à 2017 » représente une période et « États-Unis » est une entité nommée de type « lieu ».
Données liées et relations
Les relations entre entités
Les relations décrivent comment deux entités sont associées et liées entre elles.
Par exemple, Léonard de Vinci (entité Personne) est un peintre (entité Fonction) qui a réalisé la Joconde (entité Produit) pendant la Renaissance (entité Temps).
Les données liées
Le terme de données liées fait référence à un ensemble de bonnes pratiques pour publier et connecter des données entre elles, dont des entités nommées.
Le Web sémantique ne consiste pas seulement à mettre des données sur le Web. Il s’agit de créer des liens, afin qu’une personne ou une machine puisse explorer le Web des données.
Les données structurées pour lier les entités
Le balisage Schema aide à combler le fossé entre la façon dont les machines et les humains interprètent les informations. Il fournit des détails explicites sur le contenu de votre site web, garantissant que les moteurs de recherche comprennent correctement les sujets d’information proposés sur vos pages.
Le codage Schema.org avec des classement de données, dont chacun a un ou plusieurs types parents définit des types particuliers tels que « Person », « Place ». Il les caractérise par des propriétés, les décrit et les relie entre elles.
« Les schémas sont un ensemble de « types », chacun associé à un ensemble de propriétés. Les types sont organisés en hiérarchie.
Le vocabulaire se compose actuellement de 803 types, 1465 propriétés 14 types de données, 87 énumérations et 463 membres d’énumération », source schema.org.
Ainsi pour le Schema « Person », vous pouvez trouver :
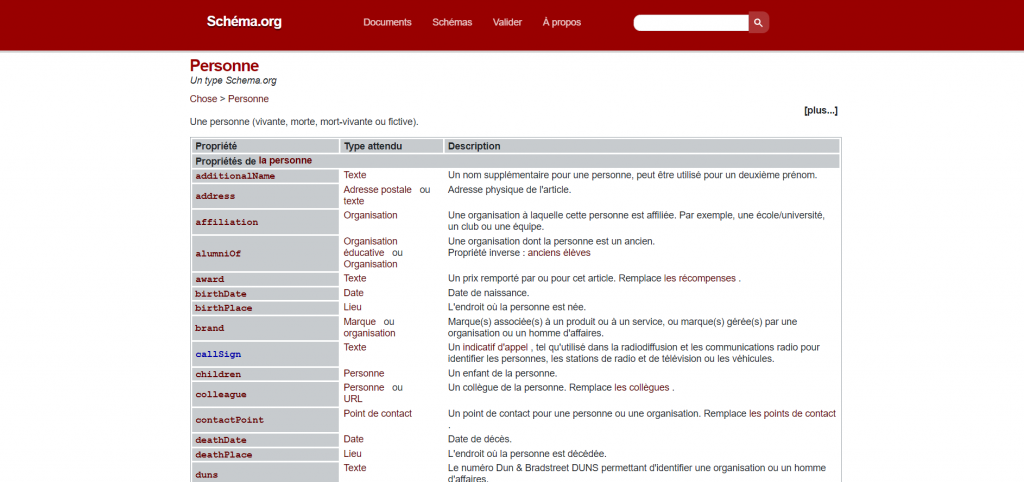
Avec les données liées, vous pouvez décrire vos entités et relier des données connexes entre elles, par exemple avec le codage Json-LD ou Schema.org.
Vous pouvez utiliser la propriété « sameAs » pour relier une entité à des informations similaires sur un site web, par exemple. Vous pouvez aussi utiliser les données structurées pour ajouter des attributs comme birthDate, birthPlace, children, e-mail ou openingHours dans le cas d’une page locale.
Relation entre les entités
Google peut identifier l’entité que vous recherchez lors d’une requête. Grâce aux entités trouvées dans le terme de recherche et le contexte de relation entre les entités, Google comprend et peut vous donner une réponse favorable.
Prenons un exemple : un moteur de recherche purement basé sur l’apprentissage des termes aurait des problèmes pour répondre à la requête de recherche de type « parent d’Obama ». Pourtant quand vous effectuez cette requête, un moteur de recherche comme Google vous répond correctement !
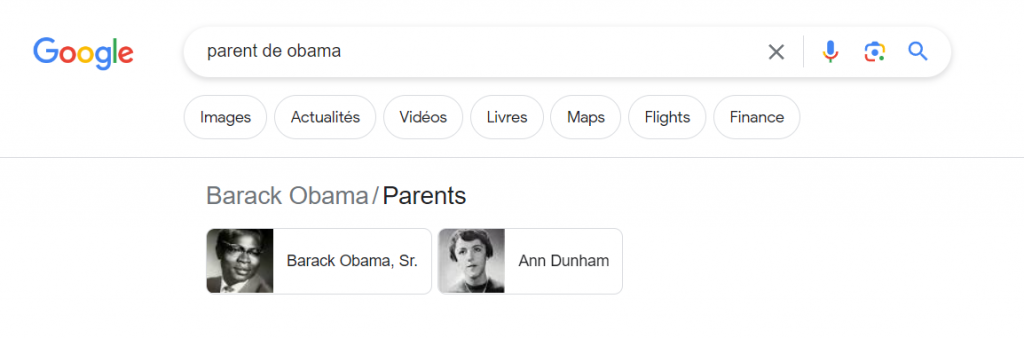
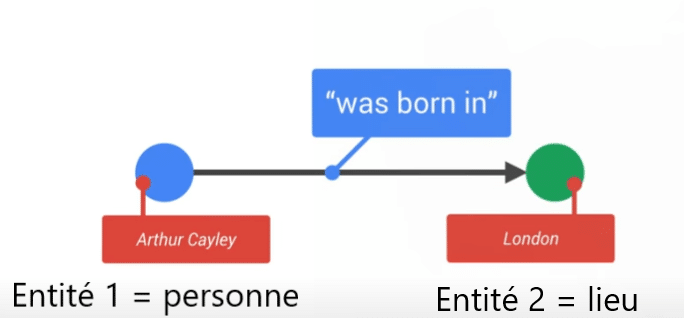
Grâce à la combinaison de recherche par terme et par entité, la réponse « Ann Dunham » peut être sortie en tant que mère de Barack Obama, comme l’explique Kristian Balog dans ce schema :
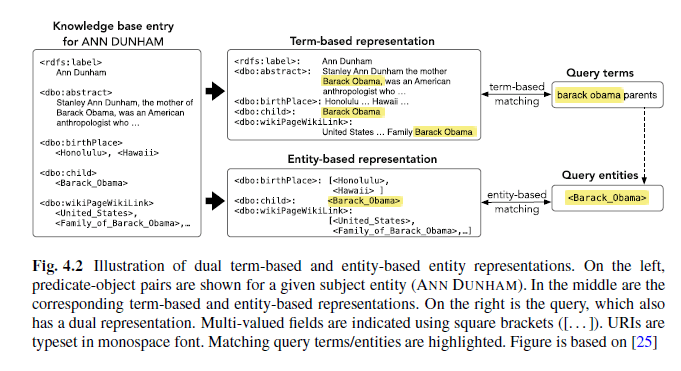
Concept et entité nommée : quelle différence ?
En traitement automatique du langage naturel (TALN ou NLP en anglais), les concepts et les entités nommées sont deux notions distinctes mais souvent utilisées ensemble dans les tâches de compréhension du langage.
Un concept en TALN fait référence à une idée ou à une abstraction générale représentée par un mot ou une combinaison de mots. Les concepts sont des idées abstraites ou des catégories qui peuvent être représentées par un ensemble de mots ou de phrases. Ils peuvent ne pas être explicitement mentionnés dans le texte, mais peuvent être compris à partir du contexte et des liens entre divers éléments d’information.
Par exemple, dans un article sur l’intelligence artificielle, des concepts tels que « apprentissage automatique » ou « réseaux de neurones artificiels » peuvent être déduits du texte, même s’ils ne sont pas directement mentionnés.
Les entités nommées et les concepts sont donc distincts mais peuvent être liés. Des entités nommées, comme « Apple » et « Microsoft », peuvent représenter le « concept d’entreprises technologiques ».
Les concepts représentent des idées générales et abstraites, tandis que les entités nommées désignent des objets spécifiques, étiquetés et concrets (pour une machine).
Les entités nommées sont donc extraites de textes ou de bases de données. Elles sont souvent utilisées pour enrichir la compréhension du texte en identifiant des informations importantes telles que les personnes, les lieux et les dates, tandis que les concepts sont utilisés pour modéliser des connaissances plus générales et organiser les informations dans un domaine donné.
Google, moteur de recherche sémantique
Un moteur de recherche sémantique comme Google fonctionne (en partie) en identifiant les entités qui intéressent les utilisateurs dans leurs requêtes.
Au lieu d’analyser les mots-clés d’une page web, Google se concentre sur la reconnaissance des sujets ou des concepts mentionnés.
Celui-ci cherche à comprendre les relations qui existent entre eux. La présence de mots-clés spécifiques n’est pas la principale préoccupation du géant californien ; il cherche plutôt à identifier les sujets ou entités pertinents abordés sur une page web.
Qu’est-ce que le Knowledge Graph de Google ?
Google essaie de comprendre les interactions dans le monde réel grâce au Knowledge Graph. C’est ce qui explique que lorsque vous recherchez des informations sur une personne connue, comme Lénoard de Vinci, un panneau de connaissance apparaît à côté des résultats de recherche.
A noter, des personnes moins célèbres peuvent tout autant apparaître.
Google a introduit le Knowledge Graph, également connu sous le nom d’arbre de connaissances, en 2012. Cette fonctionnalité présente des informations essentielles dans les résultats de recherche. Le panneau de connaissances, situé à droite des résultats, affiche des données provenant principalement de bases de connaissances telles que Wikipédia ou Wikidata.
Toutefois, il peut également contenir des informations provenant d’autres sources, comme les internautes ou les entreprises qui disposent de fiches Google My Business.
Le panneau « Connaissances » est le plus souvent utilisé pour rechercher des informations sur un lieu, une entité ou une personne.
Objectifs du Knowledge Graph
Google utilise le Knowledge Graph pour atteindre deux objectifs principaux :
1. Afficher des panneaux de connaissances pour les entités recherchées par les utilisateurs sur Internet.
2. Adapter les résultats de ses services supplémentaires en fonction des préférences et des intérêts des utilisateurs.
3. Aider les utilisateurs à accéder rapidement et « sans effort » aux informations. Il englobe un large éventail d’entités du monde réel, notamment des personnes, des lieux et des objets.
Des résultats plus personnalisés
Le moteur de recherche de Google personnalise les résultats qu’il fournit en utilisant des entités, en tenant compte des intérêts des utilisateurs et de leur historique de recherche. En effet, Google apprend aussi en fonction des requêtes « recherchées » par les autres internautes. Il les intègre dans sa base de données pour vous apporter la meilleure réponse possible en fonction de votre requête.
A savoir : étant donné que l’intention est analysée conjointement avec l’historique de recherche des utilisateurs et d’autres éléments de contexte, la même intention de recherche d’une personne XX peut générer un résultat différent d’une personne XY. En effet, deux personnes peuvent avoir une intention différente avec exactement la même requête.
Si votre page couvre les deux types d’intention, alors votre page est l’une des meilleures candidates pour le classement Web.

C’est ce qui explique que vous pouvez voir apparaître d’autres sources d’informations comme des images, des PAA (People Also Ask), des recherches associées et des lieux où vous pouvez apercevoir les oeuvres de Léonard de Vinci, par exemple.
A mesure que le Kowledge Graph. s’agrandit et s’enrichit, le moteur de recherche peut mieux comprendre les requêtes des utilisateurs et les informations disponibles sur le Web, et les relier de manière « intelligente » entre elles.
Le Knowledge Graph permet aux utilisateurs de rechercher un large éventail d’informations, telles que des objets, des personnes ou des lieux que Google connaît bien. Il peut s’agir de points de repère, de célébrités, de villes, d’équipes sportives, de bâtiments, de caractéristiques géographiques, de films, d’objets célestes, d’œuvres d’art, ou des personnes moins connues, comme vous et moi.
Lever l’ambiguïté
Le Knowledge Graph. permet de lever l’ambiguïté lors du traitement de requêtes linguistiques.
En utilisant le Knowledge Graph, les utilisateurs peuvent accéder rapidement à des informations pertinentes en rapport avec leur requête. Cette technologie constitue une avancée cruciale dans le domaine de la recherche et dans le développement d’une expérience de recherche future qui tire parti de la connaissance collective de l’internet et interprète le monde d’une manière similaire à celle des humains.
Les applications de la reconnaissance d’entités nommées
La NER a de nombreuses applications pratiques dans divers domaines, notamment :
- Recherche d’information : la NER permet d’améliorer la pertinence des résultats de recherche en identifiant les entités clés dans les documents.
- Indexation et recherche d’information : les entités nommées détectées dans des documents peuvent permettre de construire des index que pourront exploiter les moteurs de recherche mais aussi les LLM.
- Veille concurrentielle : elle aide les entreprises à suivre les activités de leurs concurrents en analysant automatiquement les publications en ligne.
- Gestion de réputation : la NER peut être utilisée pour surveiller l’image d’une marque ou d’une personnalité publique en identifiant les mentions dans les médias sociaux et autres sources de popularité en ligne (Google Trends notamment).
- Apparaître dans Google Search via un Knowledge Graph.
- Maximier ses chances d’apparaître avec SGE (Search Generative Experience de Google) et en mode conversationnel avec Bard (devenu Gemini) ou autre chatbot associés au LLM (Large Language Models).
Les défis de la reconnaissance d’entités nommées
Malgré ses avantages, la NER présente également des défis et des limites. Parmi ceux-ci désignés :
- Ambiguïté : les entités peuvent être ambiguës en fonction du contexte, rendant leur identification parfois difficile pour les algorithmes.
- Variabilité linguistique : la NER doit gérer les variations de langage, comme les synonymes, les abréviations, les dialectes et les erreurs orthographiques.
- Adaptation aux nouveaux domaines : les modèles de NER doivent être régulièrement mis à jour pour s’adapter aux évolutions du langage et des connaissances.
- Le type de texte.
- Le type d’entité que l’on souhaite reconnaître.
Dans son livre « Entity-Oriented Search« , Kristian Balog explore les complexités de la définition des entités dans le domaine des moteurs de recherche et de la recherche d’informations. Balog reconnaît que la structure des entités et leurs caractéristiques peuvent varier considérablement en fonction du domaine auquel elles se rapportent.
Comment faire du SEO avec les entités nommées
L’une des stratégies efficaces pour optimiser le contenu en SEO est probablement le regroupement thématique ou topical cluster.
L’idée est de créer du contenu web pour chaque sujet, et de montrer à Google que vous couvrez tous les sujets (sur ce thème) et ce, de manière holistique. Pour cela, chaque sujet possède :
- Une page pilier qui devra être la page principale.
- Des pages secondaires (ou pages satellites) aux informations détaillées sur chaque sous thématique.
- Le maillage interne (les liens) entre les pages doit être naturel réfléchi, tout comme le choix du texte d’ancrage.
Créer des pages pour l’intention de recherche
Le marketing de contenu thématique est directement lié à l’approche par entité. Vous devez montrer à Google que vos pages sont complètes sur un sujet, qu’elles mentionnent les entités qu’il s’attend à trouver.
En créant des pages « piliers » et des pages satellites, vos contenus peuvent répondre à toutes les intentions de recherche sur un sujet donné.
AlsoAsked et Google NLP : outil de SEO sémantique
AlsoAsked
AlsoAsked est un outil de référencement sémantique. Il utilise des données pour fournir les questions les plus étroitement liées à la requête d’un utilisateur.
En plus de vous aider à améliorer votre contenu, cet outil vous aide à répondre aux différentes intentions de recherche de vos cibles.
Démontrer aux moteurs de recherche que votre page traite l’ensemble du sujet vous aide également.
L’optimisation sémantique du contenu des moteurs de recherche nécessite une compréhension approfondie de l’intention des utilisateurs.
Pour y parvenir, un outil de référencement sémantique peut fournir des informations instantanées et non filtrées sur les recherches effectuées par les utilisateurs.
Utiliser l’API Google Cloud Natural Language
Pour mieux comprendre les liens, lever les ambiguïtés et savoir si votre sujet est holistique, vous pouvez vous servir de l’API Google Cloud Natural Language.
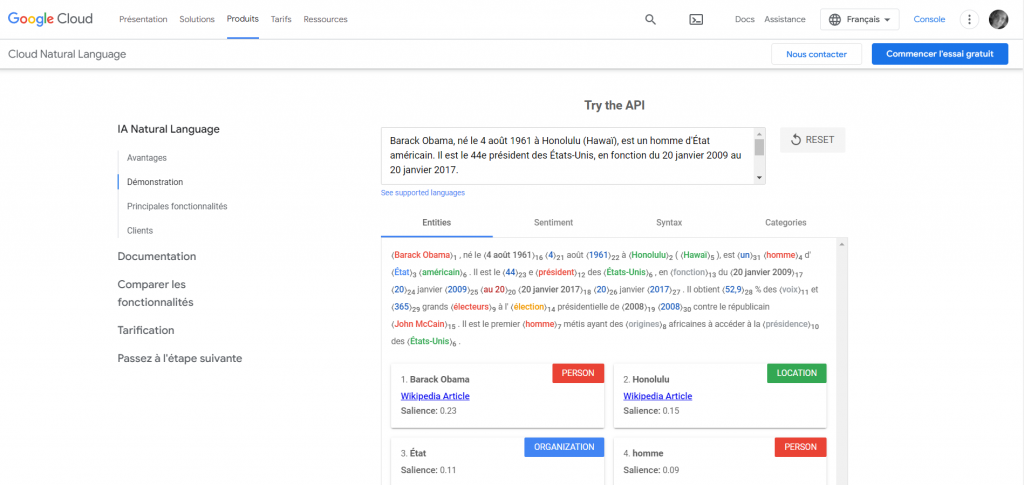
Réfléchissez à la manière dont le contexte (contenu) particulier de votre site web (et de votre page web) s’aligne sur votre activité principale.
Réfléchissez aux différentes formes d’intentions de recherche qui existent, contrôlez si elles se rapportent à votre entité principale et si vous couvrez l’ensemble de votre sujet.
Vous pouvez aussi vous servir de « Entity Indexing checker » de l’outil Inlinks.
Autres outils de référencement sémantique
L’IA est très utile pour prendre de l’avance. Demandez à GPT-4 de générer « une compilation des intentions de recherche probables pour les personnes effectuant une recherche sur Google [requête] », et vous obtiendrez une liste complète de suggestions.
Utilisez le prompt suivant : » Fournis une liste des intentions de recherche probables pour quelqu’un qui recherche sur Google « Barack Obama ». Donne-mopi la liste des entités nommées qui se rapportent à cette personne ».
Vous pouvez aussi vous servir de logiciels de génération de topic cluster pour rassembler et trouver toutes vos idées de contenus : Contentsprout AI, Google Trends et Text Razor.
Ce dernier vous donnant des scores de pertinence (relevance score) en fonction des utilisations des entités et de vos contenus ainsi que des topics à travailler.
Autres outils pour vous aider
Voici quelques outils pour élargir votre sémantique :
- Onelook.com
- Conceptnet.io
- Visuwords.com
- RelatedWords.org
- WordNet
- Knowledge Graph API Search
- Inlinks
- Wordlift
- Wikipédia
- Wikidata
- Logiciel Texte Razor
- Google Trends
Comment Google utilise les entités pour classer les pages Web ?
Google s’appuie sur les entités nommées (EN) pour indexer les pages web et fournir des résultats de recherche plus précis et plus pertinents.
En intégrant les entités nommées dans vos contenus, le moteur de recherche de Google comprend mieux leur sens en analysant leur contexte.
Comment optimiser pour les entités
Les référenceurs doivent se rappeler que Google ne recherche pas les mêmes informations remaniées. Vous pouvez copier ce que font les autres, mais des informations uniques sont la clé pour devenir un site d’autorité.
Voici les éléments clés à prendre en compte lors de l’optimisation des entités pour la recherche :
- Inclure des mots sémantiquement liés sur une page et relier les entités entre elles.
- Relier les données non structurées, les données semi-structurées et les données structurées sur une page.
- Travailler votre EEAT pour Expertise, Experience, Authoritativeness et Trustworthiness (expertise, expérience, autorité et confiance en français).
Rappel : pour comprendre les entités, il est important de connaître les trois types de structures de données utilisées par les algorithmes :
- Les descriptions d’entités non structurées sous formes d’hyperliens sont ajoutées de chaque entité à toutes les autres entités mentionnées dans sa description. Les données peuvent être du multimédia (photos, vidéos, documents scannés), des données géospatiales, de l’audio ou encore des e-mails.
- Les descriptions d’entités semi-structurées (comme Wikipédia). Ce sont des meta données (avec des caractéristiques) cataloguées.
- Les données structurées (wikidata et JSON-LD) où les triplets RDF définissent un graphe (c’est-à-dire le graphe de connaissances). Les exemples typiques de données structurées sont les noms, les adresses, la géolocalisation, etc.
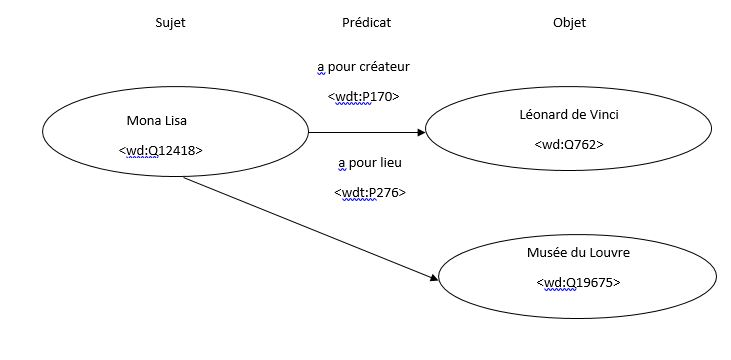
Utiliser le balisage Schema.org
En utilisant les balises de schéma, vous clarifiez les données et présentez les informations importantes et pertinentes de la manière la plus simple possible à Googlebot.
La propriété Schema.org « sameAs » peut être utilisée pour référencer les URL de pages web apparentées. Les moteurs de recherche sont ainsi informés que le contenu de ces URL possèdent des liens entre des entités apparentées.
Connecter vos données structurées
InLinks ou Wordlift sont des outils uniques qui utilisent des données structurées pour générer et lier automatiquement toutes les entités pertinentes de vos pages. Ces outils vous permettent aussi :
- de travailler sur les entités ;
- d’effectuer un maillage interne pertinent ;
- de connaître les topics clés à mettre en avant dans vos pages web ;
- de savoir si votre article couvre l’ensemble d’un sujet ;
- de coder en JSON-LD ;
- de créer des contenus exhaustifs.
About, mentions et sameAS
La valeur « about » est importante car elle met en évidence les principales entités de votre texte.
En revanche, la valeur « mentions » est moins importante, mais elle relie tout de même les entités liées au sujet principal.
Si vous prenez l’une des pages d’un de mes articles sur le référencement local, vous pouvez voir le balisage schema suivant :
L’entité principale de la page est déclarée, la valeur about est indiquée, des mentions sont utilisées et SameAs est incorporé tout comme le FAQs schema.
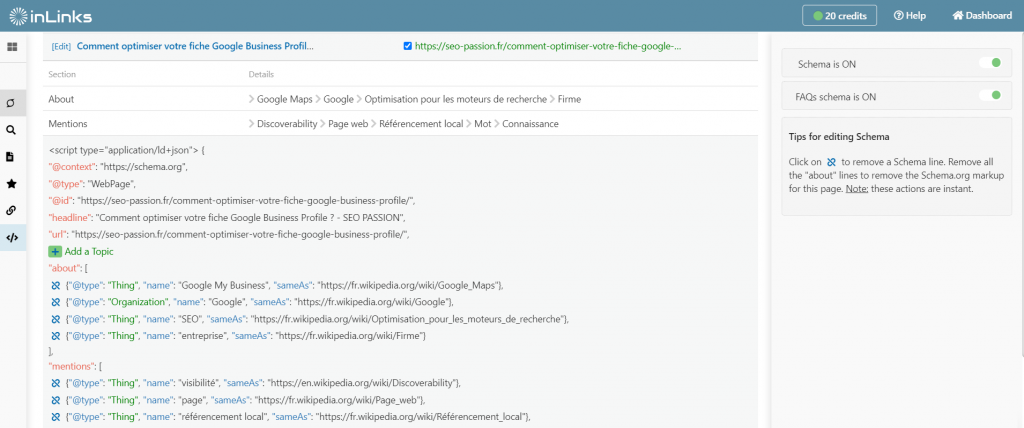
Ces balisages envoient un message extrêmement clair à Googlebot afin qu’il comprenne le contenu et qu’il sache de quoi il parle et par qui il a été écrit.
Page à propos et score de confiance
Si vous voulez vous positionner et démontrer votre autorité aux yeux de Google, vous devez obtenir un score de confiance, c’est-à-dire lui démontrer que vous êtes fiable et réel. Cette confiance dans la compréhension de ce que vous faites et ce que vous dites est le déclencheur pour que Google vous affiche dans son Knowledge Panel.
Vous pouvez vous servir de votre page à propos pour démontrer et rédiger sur vous (ou votre organisation) pour que le moteur de recherche comprenne qui vous êtes. Vous pouvez également coder en JSON pour relier les entités entre elles et celles vous concernant.
Tendances actuelles et avenir de la reconnaissance d’entités nommées
Les entités jouent un rôle crucial dans la connexion des données non structurées et structurées. Elles permettent d’améliorer la compréhension sémantique des textes non structurés et, à leur tour, les sources textuelles peuvent être utilisées pour alimenter des bases de connaissances structurées.
Les entités nommées facilitent une meilleure compréhension du texte, tant pour les humains que pour les machines. Les humains peuvent souvent résoudre l’ambiguïté des entités en tenant compte du contexte environnant, mais cela pose parfois des problèmes importants aux machines.
Les avancées en matière d’intelligence artificielle et de machine learning ont un impact significatif sur le développement de la NER. Parmi les tendances actuelles, on peut citer l’utilisation de techniques d’apprentissage profondes, telles que les réseaux neuronaux, pour améliorer la précision et la robustesse des modèles.
L’avenir de la NER pourrait inclure une meilleure intégration avec d’autres technologies d’analyse sémantique pour offrir une compréhension plus approfondie et nuancée des textes.
De plus, l’émergence de grands modèles multilingues couplée à l’IA générative (LLM) permet déjà une reconnaissance plus large et plus précise des entités nommées dans diverses langues. Une chose demeure : la pertinence et la qualité des documents restent les maîtres mots que ce soit pour des humains ou des machines.
Pour créer un contenu unique et précieux, il ne suffit pas de reprendre des mots ou des textes existants. Il faut ajouter de la valeur et de présenter une perspective nouvelle pour vos lecteurs et pour les moteurs de recherche.
SGE (Search Generative Experience) et entités nommées
La recherche sémantique façonne déjà l’avenir de la recherche. La montée en puissance des moteurs de recherche génératifs alimentés par l’IA, comme Google Search Generative Experience, est en train de propulser la technologie sémantique vers de nouveaux sommets.
Des moteurs de recherche plus puissants
Avec la révolution de l’IA et l’émergence des expériences de recherche générative, les moteurs de recherche possèdent désormais une capacité inégalée à comprendre les subtilités et la signification du langage humain.
L’IA générative de Google (SGE) utilise déjà des modèles d’IA pour générer des réponses à une requête de recherche particulière. Les applications d’IA générative (GPT, BARD et PaLM) acquièrent des connaissances en mode « zero-shot« , c’est-à-dire sans disposer de données de formation ou d’exemples spécifiques pour cette tâche.
Les IA génératives doivent simplement s’assurer que le corpus de données sous-jacent provient de sources fiables. Les entités nommées et les panneaux de connaissances deviennent donc des références.
Gagner la confiance des moteurs de recherche en utilisant les entités
La capacité de Google à générer des réponses avec des descriptions, à poser des questions complémentaires et à afficher les cartes du Knowledge Panel repose sur sa compréhension des informations accessibles et sur la confiance qu’il leur accorde.
Savoir utiliser les entités nommées joue un rôle important voire fondamental pour figurer et devenir visible lorsque Google SGE sera activé en France.
L’obtention d’un panneau de connaissances sur Google n’est pas réservée aux personnes connues. Google ne privilégie pas la notoriété dans le sens où nous la connaissons. Son principal objectif est de comprendre pour toujours donner la meilleure information à ses visiteurs. Il est de votre responsabilité de fournir des informations exactes et de renforcer la confiance de Google dans votre propre compréhension. C’est pourquoi, Google SGE pourrait également utiliser le concept EEAT pour sélectionner ces sources et n’accéder qu’à celles qui appartiennent à une certaine classe de qualité.
3 choses que vous pouvez faire aujourd’hui pour vous préparer à la recherche par l’IA générative
- Créer du contenu de qualité qui relève de votre expertise.
- Créer des contenus utiles, fiables et axés sur l’humain.
- Optimiser votre contenu avec le balisage de schéma connecté (lier votre contenu à des bases de connaissances externes et reconnues).
- Mesurer et suivre vos performances.
Conclusion
Travailler les entités nommées reste à la fois pertinent et complexe, mais comprendre et relier les entités dans vos contenus, c’est aussi ouvrir la voie à un SEO plus technique, en relation avec l’IA générative de demain.
Sources de l’article :
- Hiérarchie étendue des entités nommées par Satoshi Ketine, Kiyoshi Sudo et Chikashi Nobata
- Entity-Oriented Search par Krisztian Balog , Information Retrieval Series (INRE, volume 39)
- Réécriture de requêtes avec détection d’entités, brevet Google
- Affiner les requêtes de recherche, Google Patent
- Associer une entité à une requête de recherche, Google Patent
- Classement des résultats de recherche en fonction des métriques d’entité, brevet Google
- Entity SEO: The definitive guide, SEJ
- How to optimize for entities, SEJ
- Blog Google The Keyword, Pandu Nayak
- Schemantra, Un guide des outils du Web sémantique et du référencement sémantique
- Google Hummingbird : Là où aucune recherche n’est allée auparavant, Wired, Jeremy Hull
- Schema app what is semantic seo, what you need to know
- Créer des contenus utiles, fiables et axés sur l’humain, Google Search Central
