

Recherche visuelle, l’avenir de la recherche locale ? Quelles technologies utilise Google pour interpréter nos images et les mettre en avant ? Quelles sont les différentes implémentations de la technologie de recherche visuelle en référencement et en SEO local ? Et comment Google utilise désormais l’AI first, avec un accent particulier sur le machine learning et la vision par ordinateur ?
Qu’est-ce que la recherche visuelle ?
La recherche visuelle ne doit pas être confondue avec la recherche d’images. Alors que la recherche d’images vous oblige à utiliser des mots-clés (et donc du texte ou votre voix) pour trouver des images pertinentes pour votre requête, la recherche visuelle utilise l’image elle-même comme requête.
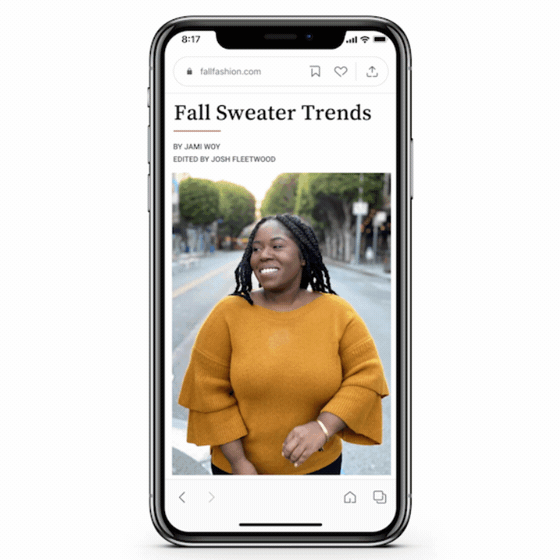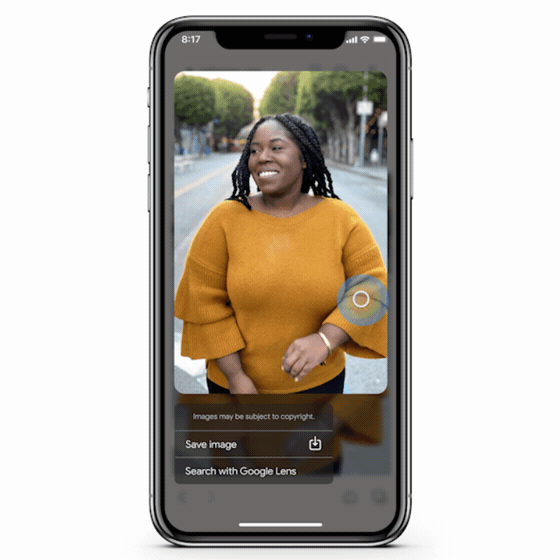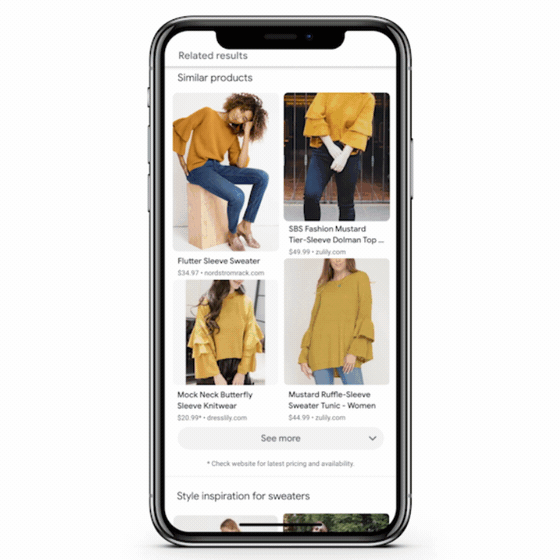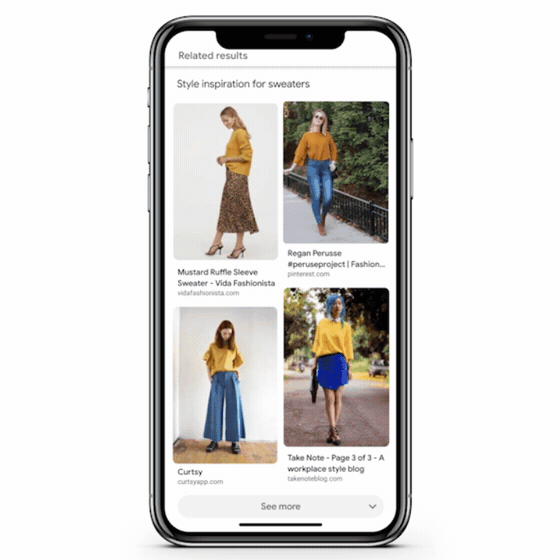
De nos jours, les utilisateurs sont plus enclins à utiliser des visuels lorsqu’ils recherchent une information. C’est pourquoi, le géant californien a fait progresser sa technologie de vision par ordinateur de manière significative, de la même manière qu’il l’a fait avec la compréhension des pages Web à travers le contenu textuel (grâce à Bert notamment).
L’une des grandes tendances évidentes dans le domaine local au cours des cinq dernières années a été l’utilisation croissante des images dans les résultats de recherche (SERP).
Les images comme facteur de classement local
Avec la compréhension croissante du contenu, de l’image, des expressions faciales et plus encore, par les moteurs de recherche, les entreprises peuvent utiliser des images à la fois pour l’utilisateur et pour optimiser leur visibilité.

A partir de l’image d’un plat, vous pouvez, grâce à la recherche multiple (et visuelle), trouver un restaurant à proximité de vous, en interrogeant directement le moteur de recherche.
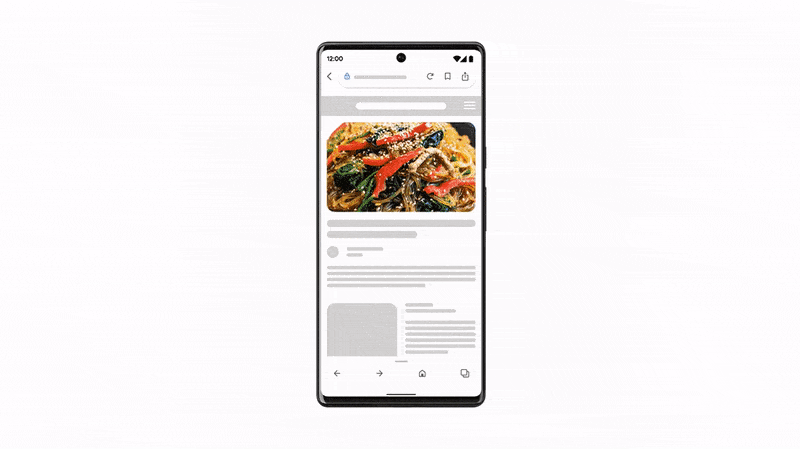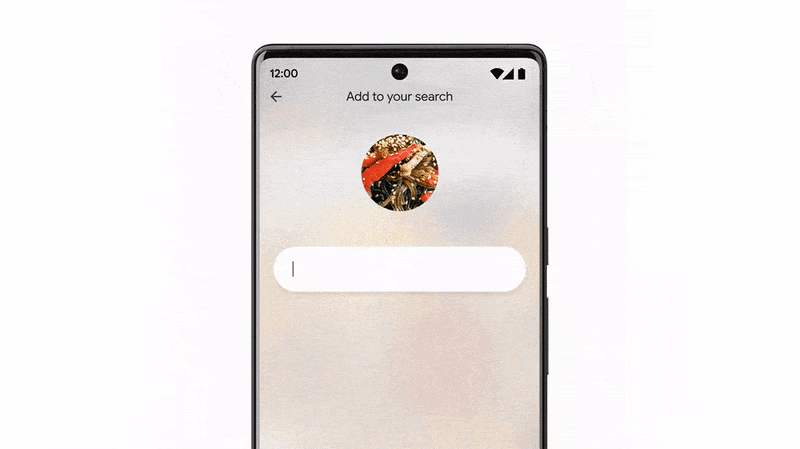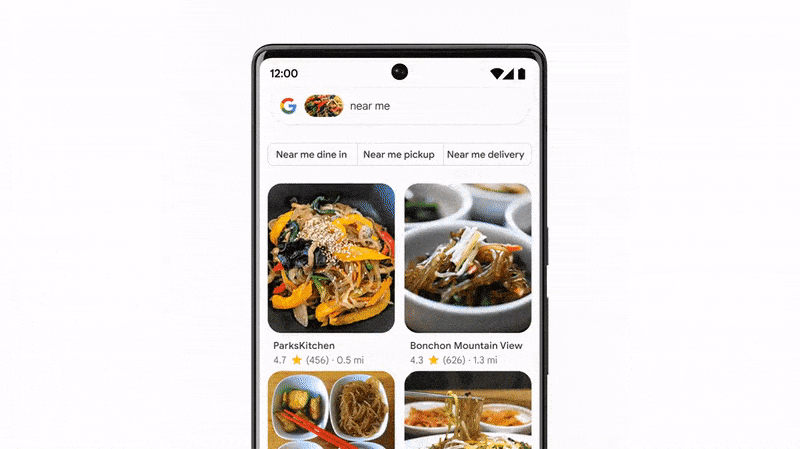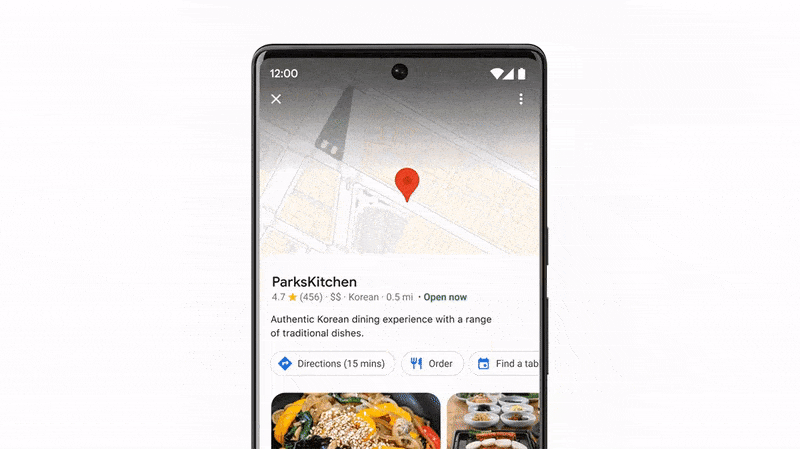
Recherche visuelle : Google Lens, Pinterest Lens, Bing et Amazon Lens
Les applications de recherche visuelle les plus courantes sont Google Lens, Pinterest Lens, Bing et Amazon Lens.
Ces applications permettent aux utilisateurs de prendre une photo ou de télécharger une image depuis leur appareil, puis de rechercher des informations grâce à l’image importée.
Google Lens, par exemple, peut identifier des objets, des lieux, des œuvres d’art, des plantes et des animaux. Il peut également traduire des langues, copier du texte et même trouver un restaurant avec la photo du plat que vous lui soumettez.
Pinterest Lens est une application similaire qui se concentre sur la recherche d’inspiration visuelle. Elle permet aux utilisateurs de trouver des images et des vidéos liées à leurs intérêts.
Bing et Amazon Lens sont des applications de recherche visuelle plus récentes qui sont encore en développement. Cependant, elles offrent déjà un certain nombre de fonctionnalités vraiment intéressantes, telles que la possibilité de trouver des produits similaires à ceux que vous voyez dans une image.
Les images jouent donc un rôle intégral pour :
➡️ Améliorer les classements sur Google Images et les autres moteurs de recherche.
➡️ Augmenter les conversions
➡️ Optimiser l’image de marque d’une entreprise.
Interpréter les données visuelles
Aujourd’hui, les algorithmes sont capables de comprendre, d’évaluer et d’interpréter de plus en plus les données visuelles de la même manière que les humains.
L’application Google Lens, déjà très performante, est promise à de nombreuses améliorations avec la recherche multi modale et l’IA.
Comment Google voit vos images ?
La recherche visuelle vous permet de rechercher sur Internet d’une manière que les mots seuls ne peuvent pas réaliser. Le groupe Alphabet l’a d’ailleurs bien compris.
C’est pourquoi, il a priorisé ces dernières années (et continue de le faire) l’image pour rendre la recherche d’informations « plus naturelle et plus immersive« , dixit Sundar Pichai, PDG du Groupe Alphabet.
De nombreuses applications ont vu le jour dont Google Lens en 2017. D’autres, sont en phase d’essai aux USA et sont prévues en France pour 2022 et 2023 : Multisearch, Multisearch near me notamment ou encore Search with Live View (devenu Lens in Maps en 2023).
Révolutionnaires, ces applications sont basées sur la recherche multiple couplée à l’IA. D’autres fonctionnent également avec la recherche par similarité et Google Images.
Sur le blog Google, il est expliqué comment, par exemple, Google Lens, reconnaît un shiba-inu, une race de chien. Cette reconnaissance est possible et s’effectue majoritairement grâce à l’intelligence artificielle et à l’apprentissage automatique. La recherche par similarité est, elle aussi, utilisée dans certains cas.
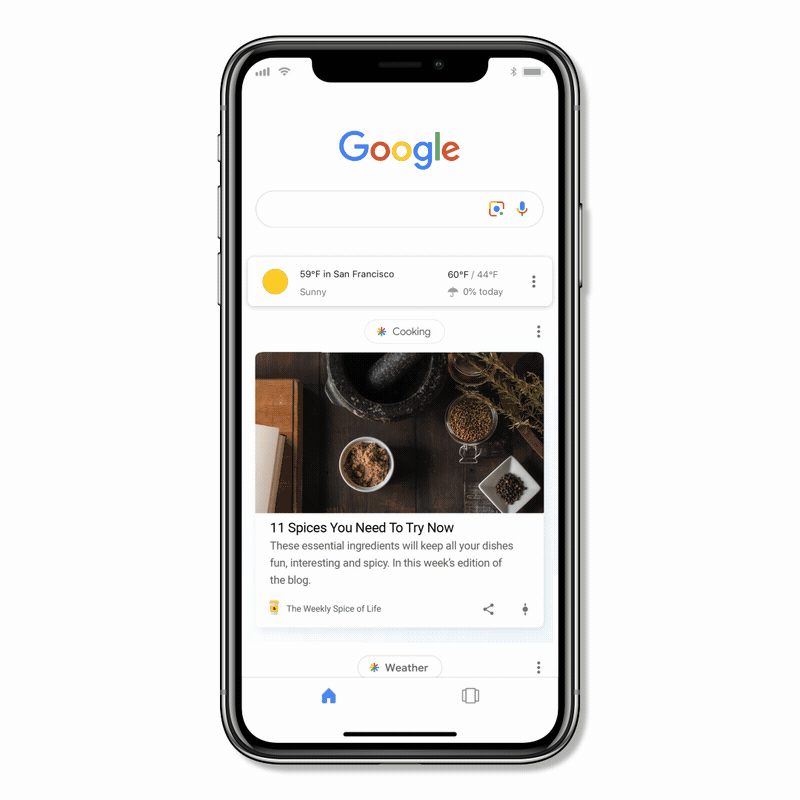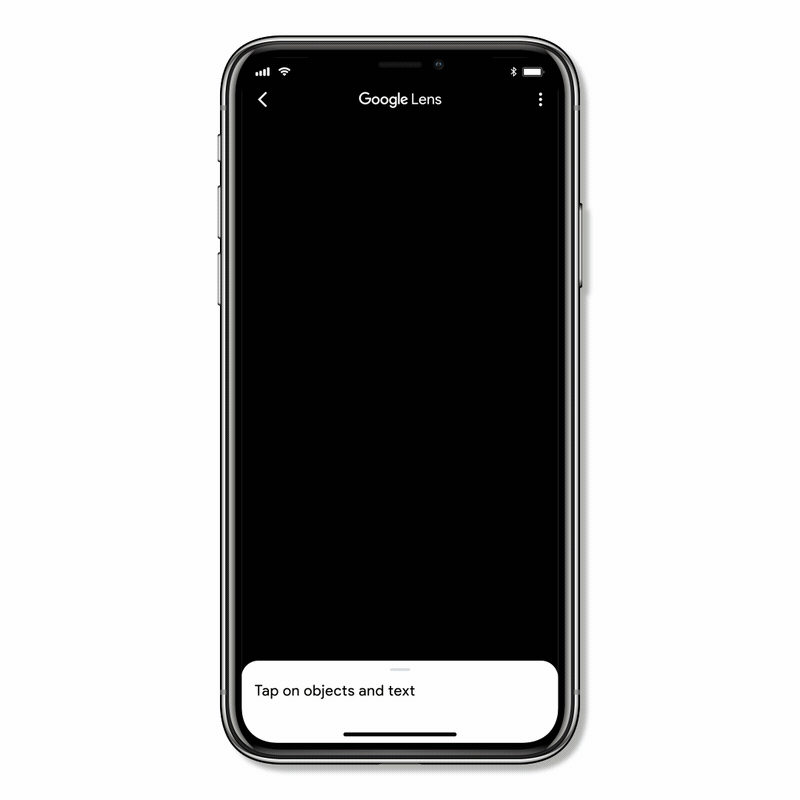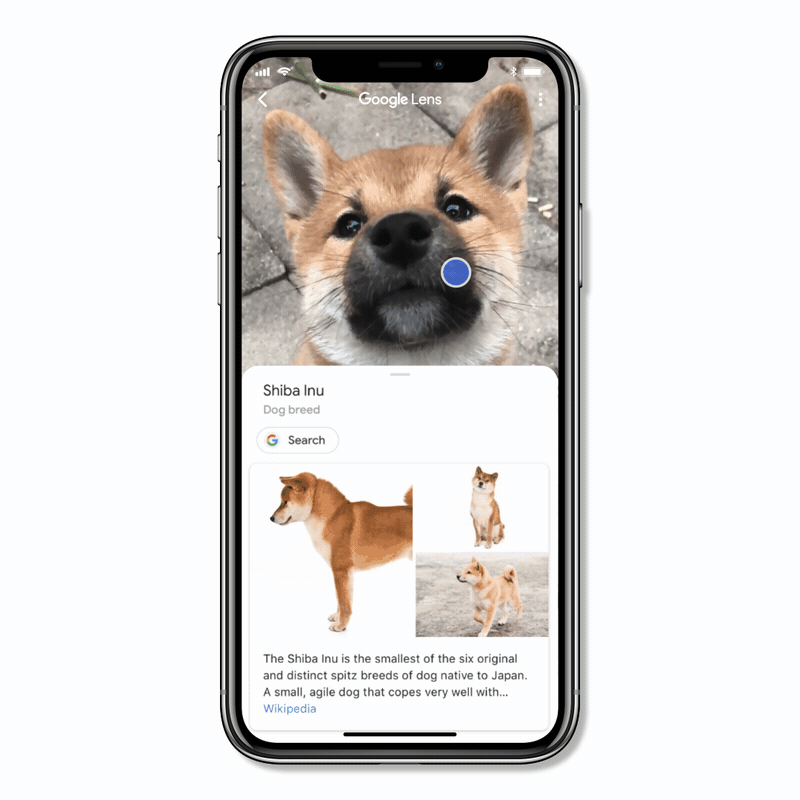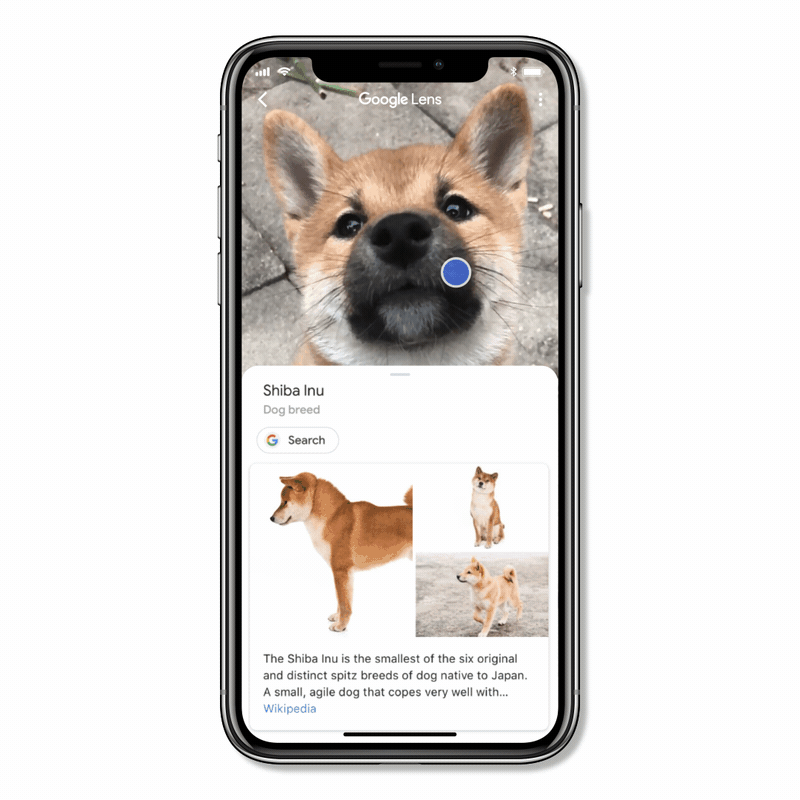
Les humains et les ordinateurs ne voient pas de la même manière !
Les humains et les ordinateurs ne voient pas de la même manière les images et le monde qui nous entourent. Et heureusement !
La création de base de données titanesques, cohérentes et utiles en machine learning est aussi importante que l’apprentissage en lui-même.
Pour mieux comprendre, voici comment un humain voit une mouette :

Et voici comment les algorithmes interprètent et lisent la même image :
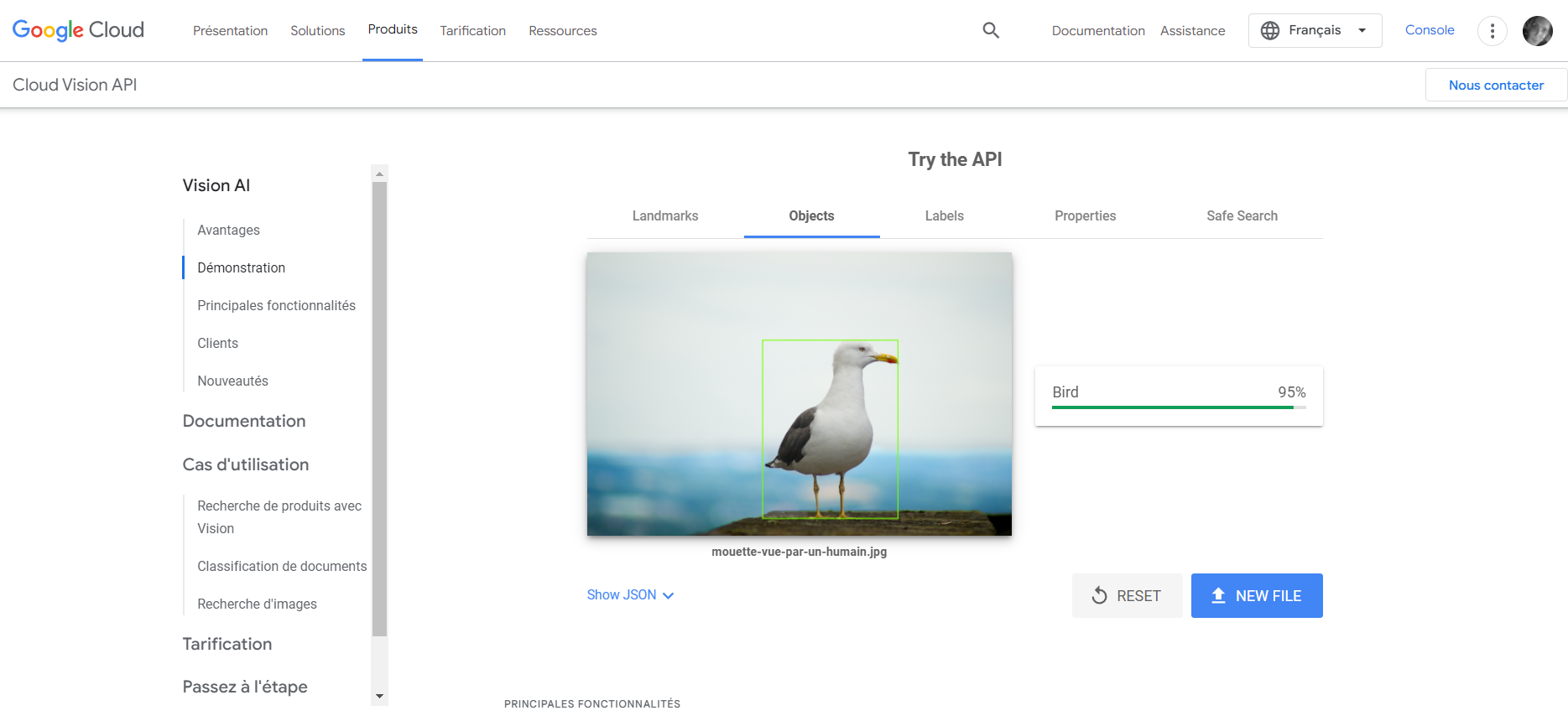
Les humains perçoivent les images, qu’elles soient numériques, imprimées ou sur un autre support, généralement de la même manière. Il n’en va pas de même pour un ordinateur.
Nous sommes tellement habitués à assimiler et à comprendre notre environnement que nous supposons que l’information visuelle va directement de nos yeux à notre cerveau. Mais ce n’est pas le cas.
La vision n’est pas innée chez l’humain. Nous avons, nous aussi, subi un apprentissage des images dès notre plus jeune âge.
C’est en observant le cortex cérébral des vertébrés que les data scientists (scientifiques) ont développé des modèles de reconnaissance d’images par apprentissage profond (Deep Learning et réseaux CNN).
Un ordinateur ne comprend que les nombres, en particulier les 0 et les 1 (binaires). Il ne reconnaît pas une image et ne se soucie pas de ce qu’elle est. Pour analyser une image, l’ordinateur doit la décomposer en pixels.
Apprentissage des images grâce aux pixels
La reconnaissance d’une image fonctionne, en partie, en analysant chaque pixel afin d’extraire de l’information, comme le ferait un œil humain.
Cette forme d’apprentissage comprend aussi la mémorisation de toutes les variantes d’images représentant le chiffre 8 : droit, penché, non centré …. Cet enseignement s’appelle la data augmentation ou augmentation de données.
Cependant, les ordinateurs ne peuvent extraire suffisamment d’informations pertinentes à partir de pixels bruts isolés. C’est pourquoi, d’autres modèles d’apprentissage (en machine learning et deep learning) ont été créés pour que les ordinateurs puissent voir les images comme vous et moi.
Les réseaux de neurones convolutionnels, également appelés CNN, ont contribué à un apprentissage majeur de la reconnaissance d’images.
Comment fonctionne la convolution ?
Un CNN (Convolutional Neural Network) est un réseau neuronal artificiel spécialement conçu pour l’analyse des pixels, dans le but de reconnaître et de traiter les images.
Au lieu d’introduire des images entières dans un réseau de neurones sous la forme d’une grille de nombres, les algorithmes utilisent l’image d’origine et enregistrent chaque résultat sous la forme d’une petite mosaïque d’image distincte.
Chaque mosaïque est appelée « couche de convolution ».

Un CNN possède différents types de couches de convolution. Celles-ci analysent l’image par zone. Elles se focalisent sur chaque partie de l’image, elle-même découpée pour être analysée puis mémorisée.
Comment Google reconnaît une image grâce aux couches de convolution ?
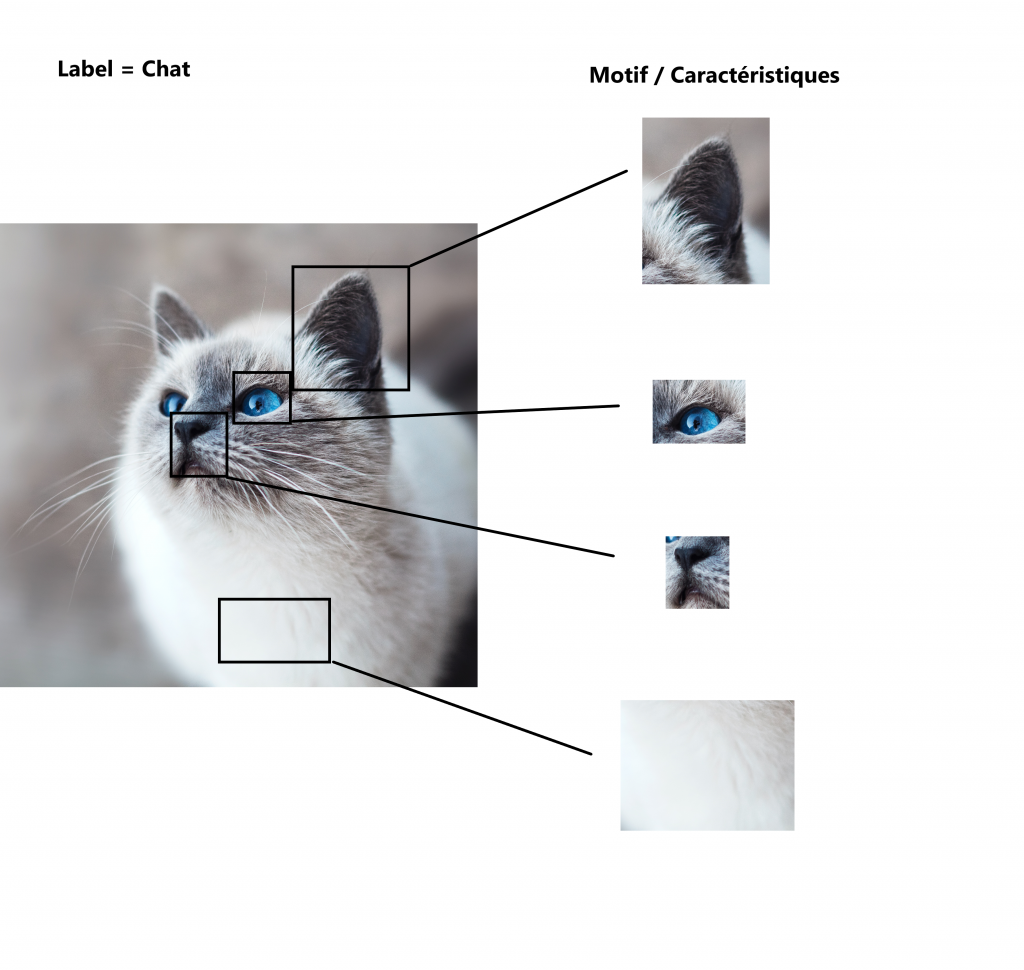
En scannant et en splittant l’image en mosaïque, le modèle détecte et apprend toutes les zones qui lui sont demandées. Ainsi, pour apprendre, par exemple, l’image d’un chat, il mémorise les endroits où se trouvent :
- des oreilles ;
- un museau ;
- des poils ;
- des pattes (etc).
Le modèle garde toutes ces caractéristiques extraites en mémoire.
Composé de centaines, voire de milliers de couches, chaque CNN est composé de couche de convolution dites “fully-connected” (FC).

L’utilisation des CNN explique ainsi la possibilité de faire une recherche visuelle sur une zone spécifique.
Dans notre exemple, l’ordinateur comprend, grâce à n’importe quelle tuile (petit carré) mémorisée (ou couche de CNN), que l’image (ou une partie de l’image) est un chat.
Ce qu’il apprend pour mémoriser un animal, il peut le faire pour une photo téléchargée et affichée sur Google Business (logo, produit et lieu avec paysage…
En résumé, les algorithmes peuvent, à partir d’une image ou d’une zone de celle-ci, déterminer un lieu, un animal, un objet ou un être humain en recherchant simplement l’une des caractéristiques apprise et mémorisée. Les ordinateurs et les algorithmes se sont considérablement améliorés ces dernières années.
L’étiquetage manuel a laissé place à la vision par ordinateur et la technologie d’apprentissage automatique. La société Alphabet recherche désormais à construire un seul modèle universel d’intégration d’images capable de représenter des objets de plusieurs domaines au niveau de l’instance, source Google Research.
La reconnaissance au niveau de l’instance (ILR) est la tâche de vision par ordinateur consistant à reconnaître une instance spécifique d’un objet, plutôt que de définir la catégorie à laquelle il appartient.
Par exemple, au lieu d’étiqueter une image comme « peinture post-impressionniste », les étiquettes au niveau de l’instance peuvent se nommer « Arc de Triomphe, place de l’Étoile, Paris, France » , au lieu du simple étiquetage « arche ».

L’apprentissage d’images reste spécifique et complexe.
Les moteurs de recherche en 2023 priorisent de plus en plus les réponses imagées. L’affichage ainsi que la manière d’effectuer nos recherches vont de devenir de plus centré sur le visuel.
L’image a donc toute sa place en SEO local et son utilisation va être grandissante. Après le mobile first, Google laisse place à l’AI first.
Est-ce que l’apprentissage automatique est la même chose que l’intelligence artificielle ?
Bien que l’« intelligence artificielle » (IA) et l’« apprentissage automatique » ne se réfèrent pas aux mêmes concepts, ils impliquent tous deux des ordinateurs qui résolvent des problèmes « faciles » pour les humains, tels que la reconnaissance d’objets dans une image.
De plus, les programmes d’apprentissage automatique permettent aux ordinateurs d’apprendre à partir d’exemples, ce que les humains font naturellement.
En résumé, l’IA et l’apprentissage automatique sont deux moyens d’enseigner aux ordinateurs à travailler plus intelligemment.
L’intelligence artificielle (IA) et la vision par ordinateur (Computer Vision)
La vision par ordinateur utilise l’apprentissage profond pour former les réseaux neuronaux à interpréter et à traiter les images.
Le domaine de la vision par ordinateur (computer vision) comprend :
- La classification d’images.
- La localisation.
- La segmentation d’images.
- La détection d’objets.
Classification d’images et détection d’objets, différences
Quelle différence entre la détection d’objet et la classification d’image ?
Qu’est-ce que la classification d’images ?
La classification des objets est simple pour nous, mais complexe pour les machines. Elle implique l’utilisation d’algorithmes pour attribuer des étiquettes à des groupes de pixels ou à des vecteurs.
Les modèles sont ainsi entraînés à reconnaître les images à l’aide d’exemples de photos ou d’étiquettes textuelles prédéfinies. Cette technologie est une étape essentielle en computer vision.
Le Machine Learning permet aux ordinateurs d’apprendre de manière autonome, en s’entraînant à partir des données.
Les premiers modèles de vision par ordinateur étaient basés sur des données brutes issues de pixels ; cependant, s’appuyer uniquement sur ces données ne donne pas une représentation fiable d’un objet dans une image en raison de facteurs variables tels que la position de l’objet, l’arrière-plan, l’éclairage, l’angle de la caméra, etc.
Pour modéliser les objets de manière plus flexible, les modèles classiques de vision par ordinateur ont ajouté de nouvelles caractéristiques.
Au lieu de prétraiter les données pour obtenir des caractéristiques telles que des textures et des formes, les réseaux de neurones convolutifs utilisent uniquement les données de pixels brutes de l’image comme entrée et apprennent à extraire ces caractéristiques et à déduire quel(s) objet(s) elles constituent. Pour en savoir plus sur la classification d’images avec les CNN, regardez cette vidéo du blog Google Developers.
La préparation des données pour un modèle d’IA est essentielle et comprend l’attribution d’étiquettes à l’aide de divers outils. Ce processus aide l’ordinateur à apprendre à distinguer les différentes catégories et à les distinguer. On parle de « Data Labeling » ou d’étiquetage de données.
En utilisant l’apprentissage automatique, les données peuvent être automatiquement étiquetées.
Un modèle est d’abord formé sur un sous-ensemble des données brutes qui a été étiqueté manuellement par des humains, puis est utilisé pour appliquer de manière autonome des étiquettes à des données brutes.

Détection d’objets
La détection d’objet est plus avancée que la classification d’image, car elle crée un cadre autour de l’objet classifié.
La détection d’objet est utilisée en computer vision pour reconnaître des images et des vidéos.
La reconnaissance d’objets est le produit d’algorithmes entraînés grâce au Deep Learning et au Machine Learning.

Également appelée boîte englobante, ou “bounding box” (cadres en vert et en rouge dans l’image ci-dessus), ces métadonnées seront exploitées par les algorithmes d’apprentissage pour pouvoir modéliser et détecter directement un objet sur de nouvelles photos ou séquences vidéos.
De nombreuses approches de détection d’objet existent. Néanmoins, elles se rejoignent toutes pour apporter aux ordinateurs une parfaite compréhension et lecture de nos images.
La détection d’objets vous indique l’emplacement des objets détectés, la classification d’images renvoie uniquement à des listes d’étiquettes.
Pour finir, la segmentation d’objets vous donne l’emplacement exact des objets et vous permet de savoir où ils se trouvent grâce à l’apprentissage de chaque pixel sur l’image (cf image suivante).

En résumé, les différentes technologies utilisées par les ordinateurs deviennent capables de “mimer” les comportements humains et les actions du cerveau grâce à l’utilisation des réseaux de neurones artificiels et de l’intelligence artificielle.
Des avancées majeures grâce à l’IA
Actuellement, Google et Google Lens utilisent l’IA (Intelligence Artificielle) avec :
- Label/Entity Detection distingue la catégorie dominante dans une image.
- Optical Character Recognition, détecte et extrait le texte d’une image.
- Safe Search Detection identifie des contenus violents, pour adultes ou inappropriés.
- Facial Detection pour détecter les visages.
- Logo Detection analyse les logos de marques et des produits.
- Landmark Detection associe un endroit et un lieu à travers le monde.
On est bien loin des simples étiquetages et titres des images intitulés : « classer-une-image.jpg » ou « restaurant-a-cannes.jpg ». Je ne dis pas qu’il ne faut plus le faire. Je dis simplement qu’il faut aller plus loin ! Votre image doit désormais correspondre, elle aussi, à l’intention de recherche de l’internaute.
Pour rappel, il existe 5 types majeurs d’intentions de recherche :
- navigationnelle ;
- informationnelle ;
- commerciale
- transactionnelle ;
- locale (implicite et explicite).
Google comprend vos images locales !
Ces dernières années, la technologie de Google pour comprendre les images a réalisé d’énormes progrès.
En effet, de la même manière qu’il a augmenté sa capacité à comprendre les pages Web à partir de texte, Google a considérablement amélioré sa technologie de vision par ordinateur, grâce au développement incessant de l’intelligence artificielle.
Les premières versions de la recherche visuelle reposaient sur des ordinateurs donnant un sens aux images en utilisant le texte intégré dans les métadonnées d’image.
Désormais, en plus de classer, étiqueter et lire vos images, Google les analyse et les interprète.
D’ailleurs, l’évolution du rôle des images sur Google Search et Google Images ne fait qu’augmenter.
Voici quelques exemples de compréhension d’images par un moteur de recherche grâce à l’IA :
Détection des points de repère
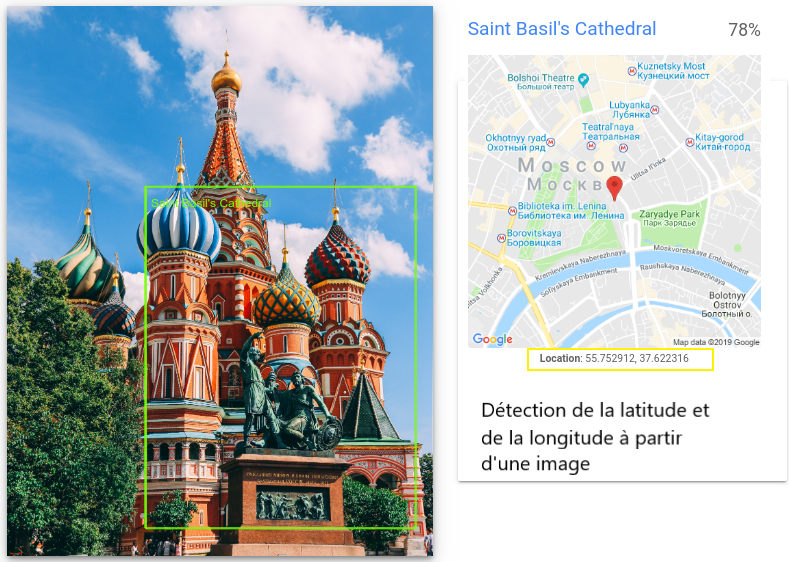
Détection des libellés

Détection des logos
Détection d’objets multiples
OCR ou Reconnaissance Optique de Caractères

L’API Vision a la capacité de reconnaître et d’extraire du texte à partir d’images. C’est pourquoi, faites attention si vous téléchargez des photos sur Google Business Profile ou sur votre site Internet.
Mettez-vous aussi à la place d’un ordinateur et posez-vous la question suivante : est-ce que Google va comprendre mon logo, le plat affiché sur le texte du menu de mon restaurant ou bien va-t-il interpréter un autre objet sur mon image ?
Pour vérifier si les photos téléchargées sur vos fiches Google my Business ou sur les pages locales de votre site Internet contiennent « les bons clichés », il vous suffit d’utiliser l’API Google Cloud Vision.
Vous verrez comment un ordinateur « voit » vos images.
API Cloud Vision
L’API Google Cloud Vision est l’une des technologies de recherche visuelle les plus utilisées actuellement. Capable de reconnaître les objets, les visages, les textes imprimés et manuscrits et d’attribuer des étiquettes aux images grâce à des millions de catégories prédéfinies.
Pour vous faire une idée de cet API, essayez gratuitement l’API Cloud Vision en téléchargeant l’une de vos images et observez la « reconnaissance » de l’image par Google.
Plusieurs onglets sont disponibles :
- Faces.
- Objets.
- Labels.
- Properties.
- Safe Search.
Vous comprendrez comment Google voit et interprète vos images. Vous pouvez ainsi interpréter si votre photo sera lue et comprise correctement. Et si elle correspond par exemple à ce que vous avez écrit en mettant en avant cette image.
La technologie de vision par ordinateur de Google ne peut pas toujours « voir » ce que nous voulons à partir de nos images. Pour vous assurer que vos images sont « lues » correctement, vous devez examiner, et le cas échéant, les modifier pour une meilleure compréhension.
Utilisation des images et conséquences en SEO local
Bien que la technologie puisse sembler complexe, innovante et déroutante pour certains, les répercussions pour les spécialistes du marketing en SEO local sont relativement simples.
Les images deviendront majoritaires et influentes dans la recherche et nos manières de rechercher des informations seront de plus en plus précises grâce aux nouvelles possibilités (filtres et ajout de texte par exemple).
Google analysera le contenu de vos photos pour vous offrir les résultats les plus pertinents.
Tout comme pour le texte, il suffira que votre image corresponde à l’intention de recherche et plaise aux algorithmes du moteur de recherche.
Quelle stratégie SEO adopter ?
Actuellement, ne vous précipitez pas pour tout modifier. Il est nécessaire de prendre du temps, d’analyser et d’observer.
Le triptyque SEO, technique, netlinking et contenu, reste de rigueur. Il vous suffit de travailler en plus vos images et vidéos.
Rendre vos images compréhensibles à tous
Que ce soit dans votre site Internet, vos pages locales ou vos fiches Google Business Profile, vous devez vous assurer que vos images sont compréhensibles par les humains et par les différentes technologies utilisées par les moteurs de recherche.
John Mueller et les représentants de Google ne cessent de le répéter : priorisez l’accessibilité numérique. Celle-ci inclut le référencement des images et leur bonne lecture par les robots de crawl et d’indexation.
Travaillez le référencement Image
Maintenir vos images pour la visibilité des moteurs de recherche reste essentiel. Voici quelques conseils :
- Élaborez un plan pour télécharger régulièrement de nouvelles images, tenez vos images existantes à jour et vérifiez qu’elles reflètent fidèlement vos offres et l’emplacement de votre entreprise.
- Placez votre image en haut du contenu HTML de chaque page.
- Créez un sitemap d’image XML pour votre site Web.
- Balisez vos images avec des données structurées (rich snippets Logo, produits et Établissement local notamment).
- Pensez à bien nommer vos photos, les compresser, à remplir l’attribut ALT et fournir de la qualité !
Optimisez votre fiche Google Business Profile
Pour vos fiches Google Business Profile, faites ce que tout référenceur en SEO local doit faire :
- Remplissez vos attributs.
- La rubrique photo de profil doit contenir votre logo, une photo d’extérieur, d’intérieur, « au travail », équipe.…). Les photos de votre profil d’entreprise Google doivent mesurer 720 px de haut sur 720 px de large.
- Créez des catégories et des produits avec des images.
- Rédigez des Google posts efficaces avec des photos, et ce, de manière fréquente.
- Vérifiez si Google comprend vos images avec l’API Cloud Vision et comment il les interprète.
- Utilisez les réseaux sociaux qui eux-mêmes priorisent les images (Instagram et Pinterest notamment).
Conclusion
Les référenceurs qui mettent d’ores et déjà l’accent sur le contenu visuel seront récompensés.
Prioriser l’expérience utilisateur, le mobile first, et l’image first, seront probablement sur le devant de la scène très prochainement.
Même si le local pack de Google est en proie à de profonds changements d’ici à 2024 en Europe ou aux USA avec la loi antitrust AICOA, les images ont, quant à elles, un affichage prometteur quoi qu’il advienne dans les années à venir.
